
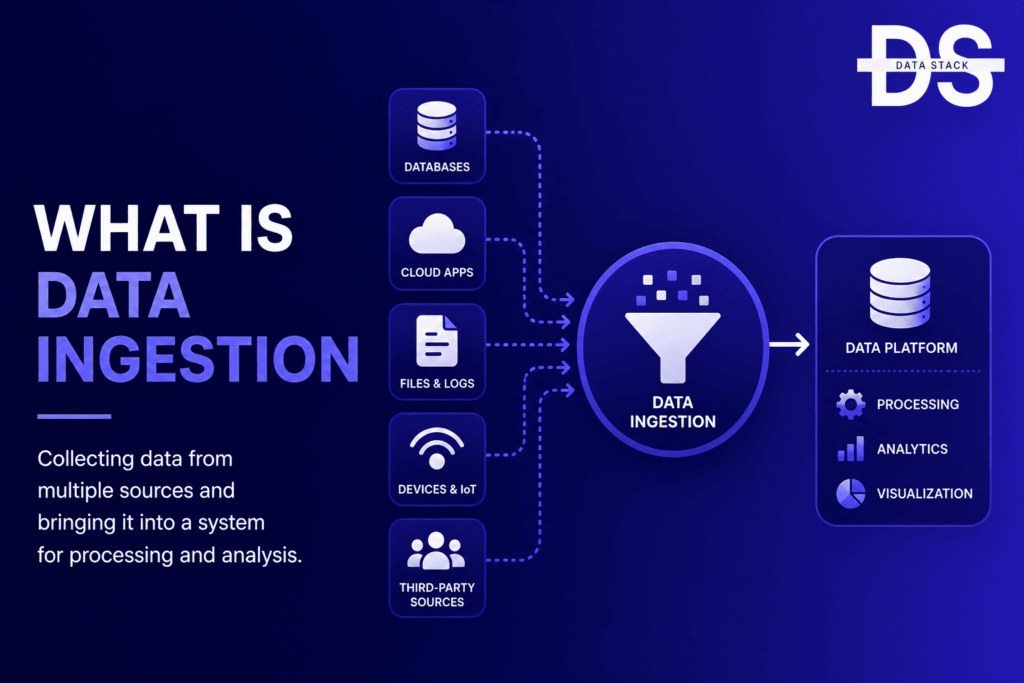
Data ingestion is the process of collecting data from different sources and moving it into a destination where it can be stored, processed, or analyzed. It is the first step in most modern data workflows because data cannot be transformed, analyzed, or used for reporting until it has been collected from source systems.
The amount of data businesses generate continues to grow every year. Customer interactions, website activity, transactions, application logs, IoT devices, APIs, and cloud applications all produce data continuously. According to IDC, the global datasphere is expected to reach hundreds of zettabytes this decade, making efficient data collection and movement more important than ever.
The challenge is that business data rarely exists in one place. A company may use Salesforce for customer management, HubSpot for marketing, Stripe for payments, Shopify for eCommerce, and Snowflake for analytics. Each platform stores information independently, making it difficult to create reports or gain insights without first bringing that data together.
This is where data ingestion comes in.
Data ingestion acts as the entry point for data. It collects information from source systems and transfers it into a destination such as a data warehouse, data lake, analytics platform, or operational database. Once the data arrives, other processes such as transformation, modeling, analytics, and machine learning can take place.
Think of data ingestion as a delivery service. Before packages can be organized in a warehouse, someone must collect them from different locations and transport them to the warehouse. Data ingestion performs a similar role for business data.
For example, imagine an online retailer wants to understand which marketing campaigns generate the most revenue. Marketing data lives in HubSpot, sales data lives in Shopify, payment data lives in Stripe, and customer support data lives in Zendesk.
Without data ingestion, those datasets remain isolated. Teams would need to manually export reports from each system and combine them in spreadsheets. With a data ingestion platform, information from all systems is automatically collected and delivered to a central location where it can be analyzed together.
Many people confuse data ingestion with data integration, ETL, or ELT. While these concepts are related, they are not the same thing. Data ingestion focuses specifically on collecting and moving data. It answers one simple question:
How does data get from the source system to the destination?
Every modern data stack relies on data ingestion. Whether a company is building dashboards, training machine learning models, creating customer analytics, or monitoring business operations, data ingestion is usually the first step that makes everything else possible.
Quick Facts About Data Ingestion
| Attribute | Details |
|---|---|
| Definition | Collecting and moving data from source systems into a destination |
| Main Goal | Make data available for storage, processing, and analysis |
| Common Sources | Databases, SaaS applications, APIs, files, IoT devices |
| Common Destinations | Data warehouses, data lakes, analytics platforms |
| Main Types | Batch, Streaming, Micro-Batch |
| Typical Users | Data engineers, analysts, architects, developers |
| Related Concepts | ETL, ELT, Data Integration, Data Pipelines |
How Data Ingestion Works
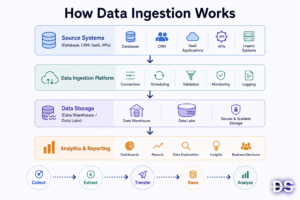
At a high level, data ingestion works by collecting information from one or more source systems and moving it into a destination system. While the process sounds simple, modern businesses often have hundreds of applications and databases generating data at different speeds and in different formats.
Consider a SaaS company that uses Salesforce for CRM, Stripe for billing, PostgreSQL for application data, and HubSpot for marketing automation.
Every day, new records are created across these systems:
- Customers sign up for free trials.
- Existing customers upgrade plans.
- Payments are processed.
- Marketing campaigns generate leads.
- Product usage data is recorded.
If the company wants to analyze all of this information inside Snowflake or BigQuery, it first needs a way to collect the data and move it into those platforms.
This is the job of data ingestion.
Most data ingestion workflows follow four main stages.
1. Data Collection
The first step is identifying where the data lives.
These sources may include:
- Databases
- SaaS applications
- APIs
- Files
- Event streams
- IoT devices
A data ingestion platform connects to these systems and determines what information needs to be collected.
2. Data Extraction
Once the connection is established, the required data is extracted from the source system.
The extraction process may involve:
- Reading database tables
- Calling APIs
- Monitoring file uploads
- Capturing events from streams
- Tracking changes in source systems
The goal is to retrieve data without disrupting production applications.
3. Data Transfer
After extraction, the data is moved from the source environment to the destination.
This transfer may happen:
- Every few minutes
- Every hour
- Once per day
- In real time
The frequency depends on business requirements and the ingestion method being used.
4. Data Storage
The final stage is storing the collected information in a destination platform.
Common destinations include:
- Snowflake
- BigQuery
- Amazon Redshift
- Databricks
- Data lakes
- Analytics platforms
Once the data arrives, it becomes available for reporting, analytics, machine learning, and other downstream processes.
The important thing to remember is that data ingestion focuses on movement rather than transformation. Its primary responsibility is getting information from point A to point B reliably and efficiently.
Data Ingestion Architecture
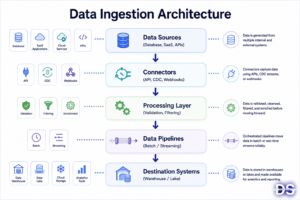
Data ingestion architecture refers to the components and systems involved in collecting, moving, and storing data. While the architecture may vary between organizations, most modern data ingestion platforms follow a similar design.
At a high level, data moves from source systems through connectors and ingestion pipelines before being stored in a destination platform.
A simple architecture may look like this:
Source Systems → Connectors → Processing Layer → Data Pipeline → Destination
As businesses grow, each of these components becomes increasingly important because they determine how quickly, reliably, and efficiently data can move across the organization.
1. Data Sources
Every ingestion process begins with a source system.
A source system is any application, database, platform, or device that generates data.
Common data sources include:
- Relational databases such as MySQL and PostgreSQL
- NoSQL databases such as MongoDB
- CRM platforms such as Salesforce
- Marketing tools such as HubSpot
- ERP systems such as SAP and NetSuite
- Cloud applications
- APIs
- Mobile applications
- IoT devices
- Log files
The number of data sources used by a business often grows over time. A startup may begin with five systems, while a large enterprise may manage hundreds of applications generating data every second.
One of the biggest challenges in data ingestion is dealing with the variety of data sources. Different systems use different formats, authentication methods, APIs, and update frequencies.
2. Data Connectors
Once a source system has been identified, the next step is establishing a connection.
This is where connectors come in.
A connector acts as a bridge between the source system and the ingestion platform.
For example, if a company wants to ingest Salesforce data into Snowflake, the connector knows how to:
- Authenticate with Salesforce
- Access Salesforce objects
- Extract records
- Handle API limitations
- Detect updates
Without connectors, engineers would need to build custom integrations for every source system they wanted to ingest.
Modern ingestion tools provide hundreds of pre-built connectors because building and maintaining custom integrations quickly becomes expensive and difficult to manage.
In many organizations, connectors are actually the most valuable part of a data ingestion platform because they eliminate a large amount of engineering work.
3. Data Processing Layer
The processing layer sits between the source and destination systems.
Its job is to prepare data for transfer and ensure it can move through the pipeline efficiently.
Depending on the platform, this layer may perform tasks such as:
- Data filtering
- Data validation
- Compression
- Deduplication
- Schema detection
- Error handling
A common misconception is that data ingestion always involves heavy transformations. In reality, many ingestion platforms perform only lightweight processing and leave complex transformations for later stages such as ETL or ELT workflows.
The main goal of the processing layer is reliability rather than transformation.
4. Data Pipelines
Data pipelines are the engines that move data from one system to another.
A pipeline defines:
- Where data comes from
- Where data goes
- How often data moves
- What processing steps occur
For example, a pipeline may be configured to collect customer data from Salesforce every fifteen minutes and load it into Snowflake.
Another pipeline may continuously stream application logs into Kafka.
Most modern businesses operate dozens or even hundreds of ingestion pipelines simultaneously.
Some support executive dashboards.
Others feed machine learning models.
Some exist solely to ensure compliance reporting remains accurate.
When pipelines fail, data stops flowing. This is why monitoring and observability have become important parts of modern data ingestion architectures.
5. Destination Systems
The final component is the destination system.
This is where the collected data is stored after ingestion.
Common destinations include:
- Data warehouses
- Data lakes
- Lakehouses
- Analytics platforms
- Operational databases
- Machine learning environments
The destination becomes the central location where data teams, analysts, and business users can access information.
For example, a company may ingest data from fifty different systems into Snowflake. While the original data remains inside those source applications, analysts can work from a single platform instead of accessing dozens of systems individually.
This is one of the primary reasons data ingestion is so important in modern data stacks.
Without a destination system, collected data would have nowhere to go and would provide little business value.
Types of Data Ingestion
Image 3: Types of Data Ingestion
Not all data ingestion processes work the same way.
Some businesses only need reports once per day. Others need information updated every few seconds.
As a result, different ingestion approaches have emerged to support different business requirements.
The four most common types of data ingestion are batch ingestion, real-time ingestion, micro-batch ingestion, and Lambda architectures.
1. Batch Data Ingestion
Batch ingestion is the most traditional form of data ingestion.
Instead of continuously moving data, information is collected and transferred according to a schedule.
For example:
- Every hour
- Every six hours
- Every night
- Every week
Imagine a retailer that generates millions of transactions every day. Rather than processing each transaction individually, the company may collect all transactions and load them into a data warehouse overnight.
The next morning, analysts can access the updated data and create reports.
Batch ingestion remains popular because it is:
- Simple to implement
- Cost-effective
- Easy to maintain
- Reliable for reporting workloads
However, the trade-off is latency.
If data is loaded once per day, users must wait until the next batch runs before seeing updates.
For many reporting use cases, this is perfectly acceptable.
For fraud detection or operational monitoring, it is not.
2. Real-Time Data Ingestion
Real-time ingestion continuously moves data as soon as it is generated.
Instead of waiting for a scheduled batch process, updates are transferred immediately.
For example:
- A customer places an order
- A payment is processed
- A sensor generates a reading
- A user clicks a button
The event is transmitted almost instantly.
This approach is commonly used in:
- Fraud detection systems
- Financial trading platforms
- Monitoring systems
- Recommendation engines
- Customer support platforms
The primary benefit of real-time ingestion is speed.
Businesses can respond to events as they happen rather than waiting for the next batch process.
The downside is increased complexity and cost because the infrastructure must operate continuously.
3. Micro-Batch Data Ingestion
Micro-batch ingestion sits somewhere between batch ingestion and real-time ingestion.
Instead of processing data once every few hours or continuously in real time, micro-batch ingestion processes small groups of records at frequent intervals.
For example, data may be collected and loaded every:
- 30 seconds
- 1 minute
- 5 minutes
- 15 minutes
To business users, the data often appears almost real time even though it is technically processed in batches.
This approach has become popular because it provides a balance between speed and complexity.
Consider a SaaS company that wants dashboards updated frequently but does not need second-by-second updates. Instead of building a complex streaming architecture, the company may simply ingest new records every five minutes.
Benefits of micro-batch ingestion include:
- Lower infrastructure costs than streaming
- Easier implementation
- Near real-time reporting
- Better scalability for many workloads
Many modern cloud data platforms rely heavily on micro-batch processing because it provides most of the benefits of real-time ingestion without the operational complexity.
4. Lambda Architecture
Lambda Architecture combines both batch and real-time processing.
The idea behind Lambda Architecture is simple:
Some workloads require historical accuracy while others require immediate visibility.
Instead of choosing one approach, the architecture supports both.
A Lambda Architecture typically contains:
- A batch layer
- A streaming layer
- A serving layer
The batch layer processes large volumes of historical data and ensures accuracy.
The streaming layer processes incoming events as they happen.
The serving layer combines results from both systems and makes them available to users.
For example, an online retailer may:
- Process years of sales history using batch ingestion
- Process new purchases in real time
- Display both views in the same dashboard
This approach provides fast insights while maintaining long-term accuracy.
Although Lambda Architecture was extremely popular in the early days of big data, many organizations now use simpler streaming and lakehouse architectures because they are easier to manage.
However, the concept remains important because it illustrates how organizations balance speed and accuracy.
Data Ingestion Methods
The type of ingestion determines when data moves. The ingestion method determines how data moves.
Different systems use different methods depending on the source, destination, and business requirements.
1. Push-Based Ingestion
In a push-based model, the source system actively sends data to the destination.
Whenever new information becomes available, it is immediately pushed to another system.
For example, a payment platform may send transaction updates directly to an analytics platform as soon as payments are processed.
The main advantage of push-based ingestion is speed.
Data can be delivered quickly without requiring the destination system to repeatedly check for updates.
However, push-based systems require source systems to support outbound communication and event delivery.
2. Pull-Based Ingestion
In a pull-based model, the destination system requests data from the source system.
Instead of waiting for information to arrive, the ingestion platform regularly checks for updates.
For example, an ingestion platform may query a CRM system every hour and retrieve newly created customer records.
Many batch ingestion systems use pull-based architectures because they are easier to implement and manage.
The trade-off is latency. Updates may not be available until the next scheduled pull operation.
3. API-Based Ingestion
API-based ingestion is one of the most common methods used today.
Most SaaS applications expose APIs that allow external systems to retrieve data.
For example:
- Salesforce API
- HubSpot API
- Stripe API
- Shopify API
Data ingestion platforms connect to these APIs, extract information, and load it into destination systems.
API-based ingestion is flexible and works well for cloud applications, but it can be limited by API rate limits and usage restrictions.
4. File-Based Ingestion
Many organizations still exchange data through files.
Common formats include:
- CSV
- JSON
- Parquet
- XML
- Avro
In this model, files are uploaded to a shared location and then processed by ingestion systems.
For example, a retailer may upload daily sales files to Amazon S3 where ingestion pipelines automatically process them.
File-based ingestion remains widely used because it is simple and compatible with almost every system.
5. Change Data Capture (CDC)
Change Data Capture focuses on identifying changes in source systems.
Instead of copying entire tables repeatedly, CDC captures only:
- New records
- Updated records
- Deleted records
For example, a customer database containing ten million records may only have one thousand updates per hour.
Rather than transferring all ten million records, CDC transfers only the changes.
This dramatically reduces processing requirements and supports near real-time analytics.
CDC has become one of the most important ingestion methods in modern data architectures.
6. Webhook-Based Ingestion
Webhooks allow applications to send notifications when specific events occur.
For example:
- A new order is created
- A customer signs up
- A payment succeeds
- A support ticket is opened
Instead of polling for updates, systems receive data automatically when events happen.
Webhooks are widely used because they provide fast updates while reducing unnecessary API requests.
Many modern SaaS integrations rely heavily on webhook-based ingestion.
Data Ingestion vs ETL vs ELT
One of the most common sources of confusion in modern data stacks is the relationship between data ingestion, ETL, and ELT.
Many people use these terms interchangeably, but they refer to different stages of the data lifecycle.
Data ingestion focuses on collecting and moving data from source systems into a destination.
Its primary goal is transportation.
ETL and ELT focus on preparing data for analysis.
Their primary goal is transformation.
For example, imagine a company collects customer data from Salesforce.
The process of moving the data into Snowflake is data ingestion.
The process of cleaning, standardizing, and enriching that data afterward is ETL or ELT.
Think of it this way:
- Data ingestion gets data into the building.
- ETL and ELT organize the building.
Without ingestion, ETL and ELT have no data to work with.
Without ETL or ELT, ingested data may be difficult to analyze effectively.
| Feature | Data Ingestion | ETL | ELT |
|---|---|---|---|
| Main Goal | Move data | Transform before loading | Transform after loading |
| Focus | Data collection | Data preparation | Data preparation |
| Processing Location | Source → Destination | Before destination | Inside destination |
| Typical Use Case | Data collection | Traditional warehouses | Modern cloud warehouses |
Understanding the distinction helps teams choose the right tools and architectures for their specific requirements.
Batch vs Streaming Data Ingestion
If you spend enough time evaluating data ingestion tools, you’ll eventually come across the debate between batch ingestion and streaming ingestion.
Some vendors position streaming as the future of data platforms, while others continue to rely heavily on batch processing. The reality is that both approaches have their place.
The right choice depends on the business problem you’re trying to solve.
Batch ingestion processes data according to a schedule. Information is collected over a period of time and loaded together as a batch.
For example, a company may:
- Load sales data every night
- Sync CRM data every hour
- Import financial records every morning
This approach works well when immediate updates are not required.
Streaming ingestion works differently.
Instead of waiting for a scheduled process, data is transferred continuously as events occur.
For example:
- A customer places an order
- A website visitor clicks a button
- A payment is processed
- A sensor records a temperature reading
The event is immediately transmitted through the ingestion pipeline.
Many teams automatically assume streaming is better because it sounds more modern. In reality, streaming adds complexity, infrastructure costs, monitoring requirements, and operational overhead.
If your executive dashboard only needs daily updates, building a real-time streaming architecture may provide little business value.
This is one of the most common mistakes organizations make.
They choose a streaming architecture because it sounds advanced rather than because the business actually needs it.
A useful rule is:
- Use batch ingestion when delayed data is acceptable.
- Use streaming ingestion when immediate action is required.
| Feature | Batch Ingestion | Streaming Ingestion |
|---|---|---|
| Data Processing | Scheduled intervals | Continuous |
| Latency | Minutes to hours | Seconds |
| Complexity | Lower | Higher |
| Cost | Lower | Higher |
| Typical Use Cases | Reporting, analytics | Monitoring, fraud detection, real-time personalization |
For many businesses, a micro-batch approach provides the best balance between simplicity and speed.
Common Data Ingestion Examples
Data ingestion can feel abstract until you see it in practice.
Let’s look at some real-world examples that show how businesses use ingestion technologies every day.
1. Ingesting CRM Data Into a Data Warehouse
A company uses Salesforce to manage customers and opportunities.
Sales managers want to track:
- Pipeline growth
- Win rates
- Revenue forecasts
- Sales performance
Instead of logging into Salesforce every time they need information, the company uses a data ingestion platform to continuously move CRM data into Snowflake.
Analysts then build dashboards in Looker or Tableau using the ingested data.
This is one of the most common ingestion use cases in modern businesses.
2. Streaming Website Events
Every action performed on a website generates data.
Examples include:
- Page views
- Button clicks
- Form submissions
- Purchases
- Searches
These events can be streamed into systems such as Kafka, Kinesis, or analytics platforms where they become available for real-time monitoring.
Streaming website activity helps businesses understand user behavior as it happens.
Companies often use this information to improve user experiences and identify conversion issues.
3. Loading Application Logs
Applications generate large volumes of logs.
These logs contain information about:
- Errors
- User activity
- System performance
- Security events
Instead of storing logs only on individual servers, organizations ingest them into centralized monitoring platforms.
This allows engineers to troubleshoot issues, identify failures, and monitor application health.
Without ingestion, log analysis becomes significantly more difficult.
4. Collecting IoT Sensor Data
IoT devices generate continuous streams of information.
Examples include:
- Temperature sensors
- Manufacturing equipment
- Smart meters
- GPS trackers
- Healthcare devices
A manufacturing company may collect millions of sensor readings every day.
Data ingestion platforms capture these events and deliver them to analytics systems where they can be monitored and analyzed.
This enables predictive maintenance, operational monitoring, and performance optimization.
Common Data Ingestion Mistakes
Many data ingestion projects fail not because of technology limitations, but because of poor planning and unrealistic expectations.
Understanding common mistakes can help organizations avoid expensive problems later.
1. Ingesting Everything Instead of What Matters
A common assumption is that more data is always better.
In reality, collecting unnecessary data increases storage costs, processing costs, and complexity.
Many organizations ingest huge amounts of information that nobody actually uses.
Before building pipelines, teams should identify:
- What questions they need to answer
- What data is required
- Who will use the information
Starting with business requirements usually leads to better results than collecting everything available.
2. Ignoring Schema Changes
Applications evolve constantly.
New fields are added.
Columns are renamed.
Data types change.
If ingestion pipelines are not designed to handle schema changes, failures become inevitable.
Many organizations only discover these problems after dashboards break or reports become inaccurate.
Schema monitoring should be part of every ingestion strategy.
3. Choosing Real-Time When Batch Is Enough
Real-time architectures are attractive because they sound modern.
However, many businesses do not actually need second-by-second updates.
If reports are reviewed once per day, a batch process may provide the same business value at a fraction of the cost and complexity.
This is one of the most expensive mistakes teams make when designing ingestion systems.
4. No Monitoring or Alerting
Data ingestion pipelines fail.
APIs become unavailable.
Connectors stop working.
Network issues occur.
Without monitoring, these problems may remain unnoticed for days or even weeks.
Successful organizations treat monitoring as a core part of ingestion architecture rather than an optional feature.
5. Poor Data Quality Validation
Moving data successfully does not guarantee that the data is correct.
For example:
- Records may be duplicated.
- Values may be missing.
- Data may arrive in unexpected formats.
If quality checks are not performed early, problems spread into reporting, analytics, and machine learning systems.
Data quality validation should be built into ingestion workflows from the start.
Data Sources Supported by Modern Ingestion Tools
One of the reasons data ingestion has become such an important category is the growing number of systems businesses use every day.
Ten years ago, a company may have relied on a handful of databases and applications. Today, businesses often use dozens or even hundreds of tools across sales, marketing, finance, operations, engineering, customer support, and analytics.
A modern ingestion platform must be able to collect information from all of these systems and move it into a centralized environment.
The broader the source support, the easier it becomes to build a complete view of the business.
1. Databases
Databases remain one of the most common sources for data ingestion.
Examples include:
- MySQL
- PostgreSQL
- Microsoft SQL Server
- Oracle Database
- MongoDB
- Cassandra
Businesses store customer records, transactions, application data, inventory information, and operational data inside databases.
Many ingestion pipelines begin by extracting data directly from these systems.
For example, an eCommerce company may ingest order and product information from PostgreSQL into Snowflake every hour for reporting and analytics.
2. SaaS Applications
Modern businesses rely heavily on SaaS applications.
These platforms often contain some of the most valuable business data.
Examples include:
- Salesforce
- HubSpot
- Zendesk
- Shopify
- NetSuite
- Stripe
- Jira
- ServiceNow
Each application generates information that can be useful for reporting, forecasting, customer analytics, and operational monitoring.
Without ingestion, this information remains trapped inside individual applications.
This is why most ingestion vendors invest heavily in connector development.
In many cases, connector coverage becomes one of the most important evaluation criteria when choosing a platform.
3. Cloud Storage Platforms
Many organizations store files inside cloud storage platforms.
Examples include:
- Amazon S3
- Google Cloud Storage
- Azure Blob Storage
These platforms often contain:
- CSV files
- JSON files
- Parquet files
- Log files
- Data exports
- Historical archives
Ingestion systems can automatically detect new files and load them into warehouses or lakes for further processing.
This approach is commonly used when exchanging data between teams, applications, and business partners.
4. Event Streaming Platforms
Event streaming systems generate continuous streams of information.
Examples include:
- Apache Kafka
- Amazon Kinesis
- Apache Pulsar
- Confluent Cloud
Unlike traditional batch data sources, event streams deliver information continuously.
Organizations often use streaming platforms for:
- Real-time analytics
- Fraud detection
- Monitoring systems
- Recommendation engines
- Operational dashboards
As businesses move toward real-time architectures, event streams are becoming increasingly important data sources.
5. IoT Devices and Sensors
IoT devices generate massive volumes of information.
Examples include:
- Manufacturing equipment
- Smart meters
- Medical devices
- GPS trackers
- Environmental sensors
A single manufacturing facility may generate millions of sensor readings every day.
Data ingestion platforms collect this information and make it available for monitoring, analytics, and predictive maintenance.
Without ingestion, much of this data would remain inaccessible or unusable.
Benefits of Data Ingestion
Data ingestion is often viewed as a technical process, but its benefits extend far beyond data engineering teams.
When implemented correctly, data ingestion helps businesses make better decisions, improve efficiency, and unlock value from their data.
1. Faster Access to Data
The most obvious benefit of data ingestion is that it makes information available where it is needed.
Without ingestion, data remains locked inside operational systems.
Marketing teams have marketing data.
Sales teams have CRM data.
Finance teams have accounting data.
Each department sees only part of the picture.
Data ingestion helps move information into centralized platforms where everyone can access consistent and up-to-date data.
This reduces delays and improves visibility across the organization.
2. Better Reporting and Analytics
Many reporting projects fail because the required data is scattered across multiple systems.
Data ingestion solves this problem by collecting information from different sources and making it available in a central location.
Analysts no longer need to spend hours gathering spreadsheets and manually combining reports.
Instead, data is already available for analysis.
This allows teams to focus on finding insights rather than preparing data.
3. Supports Modern Data Warehouses
Data warehouses depend on ingestion.
A platform such as Snowflake or BigQuery provides little value unless data can be continuously loaded into it.
Data ingestion serves as the pipeline that feeds these systems.
In many ways, ingestion is the foundation upon which modern analytics environments are built.
4. Enables AI and Machine Learning
Machine learning models require large amounts of data.
The challenge is that the required information often comes from multiple systems.
For example, a customer churn model may need:
- CRM data
- Product usage data
- Billing information
- Customer support records
Data ingestion brings these datasets together and makes them available for model training and analysis.
As AI adoption increases, the importance of reliable ingestion pipelines continues to grow.
5. Improves Operational Visibility
Many businesses need visibility into operations as they happen.
Examples include:
- Order processing
- Website activity
- Inventory levels
- Application performance
- Customer support metrics
Data ingestion helps ensure information reaches monitoring and analytics systems quickly.
This allows teams to identify problems earlier and respond faster.
6. Reduces Manual Work
Before modern ingestion platforms became common, many organizations relied on manual exports and imports.
Employees downloaded spreadsheets, emailed files, and copied information between systems.
This approach consumed valuable time and introduced errors.
Automation through ingestion pipelines eliminates much of this work and improves reliability.
Common Data Ingestion Challenges
Although data ingestion provides significant benefits, implementing ingestion pipelines at scale is not always straightforward.
As organizations add more systems and generate larger volumes of data, new challenges emerge.
1. Managing Large Data Volumes
Data volumes continue to grow rapidly.
A startup may process thousands of records per day, while a large enterprise may process billions.
As data volumes increase, ingestion systems must scale accordingly.
Poorly designed pipelines often become bottlenecks as workloads grow.
2. API Limitations
Many SaaS applications impose API limits.
For example, an application may restrict:
- Number of requests per hour
- Amount of data transferred
- Concurrent connections
These limitations can affect ingestion performance and increase synchronization times.
Teams often need to design around these restrictions.
3. Schema Drift
Schema drift occurs when the structure of source data changes unexpectedly.
New columns appear.
Fields are renamed.
Data types change.
If ingestion pipelines cannot handle these changes automatically, failures occur.
Schema drift is one of the most common causes of pipeline maintenance work.
4. Data Quality Problems
One of the biggest misconceptions about data ingestion is that if data successfully reaches a destination, the job is done.
In reality, moving bad data simply creates bad analytics.
Source systems often contain:
- Duplicate records
- Missing values
- Invalid formats
- Outdated information
- Incorrect mappings
For example, one application may store a customer as “John Smith” while another stores the same person as “J. Smith.” If these records are ingested without validation, reporting accuracy suffers.
This is why leading organizations treat data quality as part of their ingestion strategy rather than an afterthought.
5. Monitoring and Reliability
Data ingestion pipelines are expected to run continuously.
However, many things can go wrong:
- APIs become unavailable
- Connectors fail
- Credentials expire
- Networks experience outages
- Source systems change
Without monitoring, teams may not discover failures until business users report missing data.
Modern ingestion platforms increasingly include monitoring, alerting, and observability features because reliability has become just as important as data movement itself.
6. Cost Management
As data volumes grow, costs can increase rapidly.
Organizations often pay for:
- Data storage
- Data transfer
- Compute resources
- API usage
- Third-party ingestion tools
Many companies initially focus on functionality and only later realize that their ingestion architecture has become expensive to maintain.
Good ingestion design balances performance, reliability, and cost.
Data Ingestion Best Practices
Successful data ingestion projects rarely happen by accident. Organizations that build reliable ingestion pipelines usually follow a consistent set of best practices.
1. Start With Business Requirements
Before building pipelines, identify the business questions you are trying to answer.
Many teams make the mistake of ingesting data simply because it is available.
A better approach is to ask:
- Who will use the data?
- What reports are required?
- Which systems contain the necessary information?
- How frequently does the data need to be updated?
Starting with business requirements helps avoid unnecessary complexity.
2. Choose the Right Ingestion Method
Not every workload requires real-time processing.
One of the most expensive mistakes organizations make is building streaming architectures when batch ingestion would provide the same business value.
Consider:
- Batch for reporting and analytics
- Streaming for operational systems
- Micro-batch for near real-time visibility
The simplest solution that meets business requirements is often the best solution.
3. Monitor Schema Changes
Source systems evolve constantly.
New columns are added.
Fields are renamed.
Data types change.
Organizations should implement schema monitoring so ingestion pipelines can detect and respond to these changes automatically.
Ignoring schema drift almost always leads to reporting issues later.
4. Implement Data Quality Checks
Data should be validated before it becomes available to business users.
Examples include:
- Duplicate detection
- Null value checks
- Format validation
- Record count verification
- Business rule validation
A pipeline that moves incorrect data is not a successful pipeline.
5. Build Monitoring and Alerting From Day One
Monitoring should not be added after deployment.
Teams should know immediately when:
- Pipelines fail
- Data arrives late
- Connectors stop working
- Data quality thresholds are breached
Early detection prevents small issues from becoming major business problems.
6. Plan for Scale
Many ingestion systems work well during the first year and struggle afterward.
As data volumes increase, pipelines need to handle:
- More records
- More sources
- More users
- More destinations
Designing for growth early reduces the likelihood of costly redesigns later.
Popular Data Ingestion Tools
The data ingestion market has grown rapidly as organizations modernize their data stacks.
Today, businesses can choose from open-source, commercial, and cloud-native ingestion platforms.
Open-Source Data Ingestion Tools
Airbyte is one of the most popular open-source ingestion platforms. It offers hundreds of connectors and is often chosen by organizations that want flexibility and control.
Apache Kafka is widely used for streaming data ingestion and event-driven architectures. It is particularly popular for real-time use cases.
Apache NiFi provides a visual interface for building ingestion workflows and data movement pipelines.
Commercial Data Ingestion Tools
Fivetran is known for its fully managed connector approach. Organizations use it to automate data movement with minimal maintenance.
Hevo Data focuses on simplicity and ease of use, making it popular among growing SaaS companies and analytics teams.
Matillion combines data ingestion and transformation capabilities and is commonly used alongside cloud data warehouses.
Informatica remains a leading enterprise platform for large-scale data integration and ingestion projects.
Cloud-Native Data Ingestion Tools
AWS Glue provides ingestion and ETL capabilities within the AWS ecosystem.
Google Dataflow supports batch and streaming ingestion workloads on Google Cloud.
Azure Data Factory enables data movement and orchestration within Microsoft Azure environments.
The best tool depends on factors such as connector requirements, budget, scalability needs, and the overall architecture of the organization.
How to Choose a Data Ingestion Tool
Choosing a data ingestion platform is not simply about selecting the tool with the largest number of connectors.
The right platform depends on business goals, technical requirements, and future growth plans.
1. Connector Availability
Start by identifying the systems you need to connect.
A platform may have excellent features, but if it does not support your critical data sources, it may not be the right choice.
Connector coverage is often the first evaluation criterion.
2. Batch vs Real-Time Requirements
Different tools specialize in different workloads.
Some platforms focus on scheduled batch processing, while others are optimized for real-time streaming.
Understanding your latency requirements helps narrow the list of potential solutions.
3. Scalability
Consider not only current requirements but also future growth.
A platform that works well for ten data sources may struggle when the business expands to one hundred.
4. Monitoring and Reliability
Data movement is only valuable when it works consistently.
Look for features such as:
- Pipeline monitoring
- Alerting
- Error handling
- Retry mechanisms
- Observability
These capabilities often become more important than connector counts over time.
5. Total Cost of Ownership
Pricing should include more than subscription fees.
Consider:
- Platform costs
- Infrastructure costs
- Engineering effort
- Maintenance requirements
- Training costs
The cheapest option is not always the most cost-effective solution in the long run.
Data Ingestion in the Modern Data Stack
Modern data stacks are built around a simple flow:
Data Sources → Data Ingestion → Data Storage → Data Transformation → Analytics
Data ingestion sits near the beginning of this process.
Without ingestion, warehouses remain empty, dashboards stop updating, and machine learning models lose access to fresh information.
A typical modern architecture may look like this:
- Salesforce generates customer data
- Stripe generates payment data
- Product databases generate usage data
- An ingestion platform collects the information
- Snowflake stores the data
- dbt transforms the data
- Looker or Tableau visualizes the results
This flow has become the foundation of modern analytics environments.
As organizations adopt cloud data warehouses, lakehouses, artificial intelligence, and advanced analytics, the importance of data ingestion continues to grow.
Conclusion
Data ingestion is the process of collecting data from source systems and moving it into a destination where it can be stored, processed, and analyzed.
Although the concept sounds simple, it plays a foundational role in every modern data stack. Before organizations can build dashboards, run analytics, train machine learning models, or create customer insights, they first need a reliable way to collect and move data.
Whether information comes from databases, SaaS applications, APIs, event streams, or IoT devices, data ingestion ensures it reaches the systems where it can deliver business value.
As businesses continue to generate larger volumes of data, efficient ingestion pipelines will remain a critical part of modern data architectures.
Frequently Asked Questions
1. What is data ingestion in simple terms?
Data ingestion is the process of collecting data from one or more sources and moving it into a destination such as a data warehouse, data lake, or analytics platform.
2. What is the difference between data ingestion and data integration?
Data ingestion focuses on collecting and moving data. Data integration goes further by combining, transforming, and preparing data from multiple systems for business use.
3. What are the main types of data ingestion?
The most common types are batch ingestion, real-time ingestion, micro-batch ingestion, and Lambda Architecture.
4. What is streaming data ingestion?
Streaming data ingestion continuously moves data as events occur, allowing organizations to process information in near real time.
5. What is CDC in data ingestion?
Change Data Capture (CDC) is a method that transfers only new, updated, or deleted records instead of processing an entire dataset repeatedly.
6. Which tools are used for data ingestion?
Popular data ingestion tools include Airbyte, Fivetran, Hevo Data, Apache Kafka, Apache NiFi, AWS Glue, Google Dataflow, and Azure Data Factory.
7. Why is data ingestion important?
Data ingestion makes data available for reporting, analytics, machine learning, operational monitoring, and business intelligence.
8. Is data ingestion part of ETL?
Yes. Data ingestion is often the first stage of ETL and ELT workflows because data must be collected before it can be transformed and analyzed.