
According to IDC, global data creation continues to grow at an unprecedented pace as organizations generate information from cloud applications, IoT devices, databases, APIs, AI systems, customer interactions, and operational platforms. Storing data is no longer the primary challenge. The real challenge is processing it efficiently and turning it into actionable insights.
Modern organizations must process structured, semi-structured, and unstructured information across multiple environments while supporting analytics, reporting, machine learning, AI, and operational applications. Traditional processing architectures often struggle to meet modern requirements for scalability, performance, and real-time responsiveness.
This is where Data Processing Tools become essential.
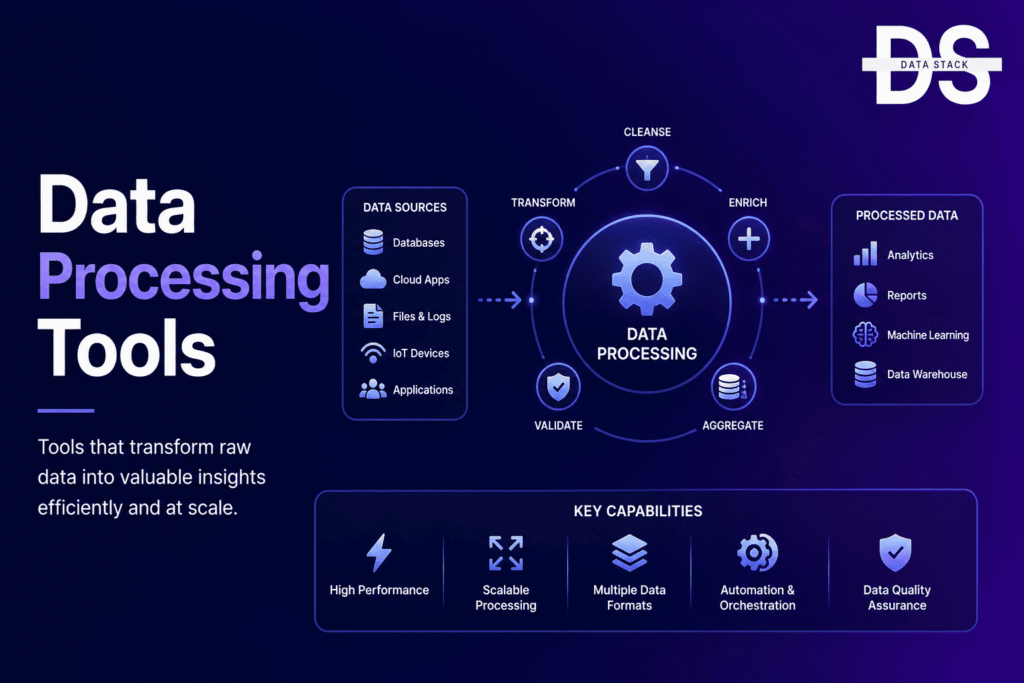
Data Processing Software helps organizations ingest, transform, enrich, validate, analyze, and distribute information across business systems. These platforms support batch processing, stream processing, real-time analytics, AI initiatives, data engineering workflows, and cloud-native architectures.
Another major trend shaping the market is the rapid adoption of AI and generative AI applications. Organizations increasingly require processing platforms capable of handling massive datasets while supporting machine learning pipelines, vector workloads, and real-time AI applications.
To identify the best Data Processing Tools, we evaluated vendors based on scalability, processing performance, cloud compatibility, streaming support, ecosystem maturity, AI readiness, governance capabilities, and enterprise adoption. Our selections include cloud-native processing platforms, enterprise data processing solutions, streaming technologies, and open-source frameworks.
What Are Data Processing Tools?
Data Processing Tools are software platforms that help organizations collect, transform, validate, enrich, analyze, and move information across business systems. These tools convert raw information into usable formats that support analytics, reporting, operational applications, machine learning, and AI initiatives. Modern Data Processing Platforms often combine batch processing, stream processing, orchestration, governance, and analytics capabilities within a unified environment.
Benefits of Data Processing Software
- Improve analytics and reporting accuracy.
- Enable real-time and batch processing workflows.
- Support AI and machine learning initiatives.
- Reduce manual data preparation effort.
- Improve scalability across cloud environments.
- Accelerate data engineering workflows.
- Support modern lakehouse architectures.
Data Processing Software Comparison
| Tool | Best For | Pricing Model | Best Fit |
|---|---|---|---|
| Databricks | Unified processing | Consumption | Enterprises |
| Apache Spark | Large-scale processing | Open Source | Engineering teams |
| Snowflake | Cloud processing | Consumption | Cloud-first companies |
| Google Cloud Dataflow | Stream processing | Usage-based | Google Cloud users |
| AWS Glue | Serverless processing | Usage-based | AWS customers |
| Microsoft Fabric | Unified analytics | Subscription | Microsoft customers |
| Apache Flink | Real-time processing | Open Source | Streaming workloads |
| Confluent | Event processing | Subscription | Event-driven architectures |
| Talend Data Fabric | Enterprise processing | Custom | Enterprises |
| Informatica Cloud Data Integration | Enterprise integration | Custom | Large enterprises |
| StreamSets | Continuous processing | Custom | DataOps teams |
| Dataiku | AI and analytics workflows | Custom | Data-driven organizations |
| IBM StreamSets | Enterprise DataOps | Custom | Enterprises |
13 Best Data Processing Tools
#1 Databricks
Databricks has become one of the most influential Data Processing Platforms by bringing together data engineering, analytics, machine learning, and AI workloads within a unified lakehouse architecture. Unlike traditional processing platforms that separate storage, transformation, analytics, and AI workflows, Databricks provides a consolidated environment capable of supporting the entire data lifecycle.
Organizations frequently choose Databricks because modern data initiatives rarely operate in isolation. Analytics teams, data engineers, machine learning practitioners, and AI developers often need access to the same datasets. Maintaining separate processing environments creates duplication, governance challenges, and operational complexity. Databricks addresses these challenges through a unified architecture built around Apache Spark and Delta Lake.
Compared with traditional enterprise platforms such as Informatica and Talend, Databricks offers greater scalability for large-scale analytics and AI workloads. Compared with Snowflake, it provides stronger support for advanced data engineering and machine learning use cases.
Key Features
- Supports batch processing, stream processing, analytics, AI, and machine learning workloads.
- Uses Apache Spark to process massive datasets efficiently.
- Provides Delta Lake capabilities for reliability and governance.
- Supports collaborative workflows across engineers, analysts, and data scientists.
- Enables real-time and large-scale processing architectures.
- Integrates with AWS, Azure, and Google Cloud environments.
- Supports generative AI, machine learning, and advanced analytics initiatives.
- Provides unified governance and operational visibility.
Pricing
Consumption-based pricing.
Best For
Organizations building large-scale analytics, AI, and lakehouse architectures.
Why Choose This Tool
Databricks is often the strongest choice when organizations need a single platform capable of handling analytics, engineering, machine learning, and AI workloads at enterprise scale.
G2 Rating: 4.5/5
Gartner Rating: 4.7/5

Showcase your software to buyers actively comparing tools. Submit your product for editorial review and get featured on Data Stack Hub.
Submit Your Tool →#2 Apache Spark
Apache Spark remains the foundation of many modern Data Processing architectures and is widely regarded as one of the most important open-source technologies in the data ecosystem. The framework enables distributed processing across massive datasets while supporting analytics, machine learning, streaming, and operational workloads.
Organizations choose Spark because traditional processing engines often struggle with scale and performance. Spark’s distributed architecture allows teams to process terabytes and petabytes of information efficiently across clusters. Unlike managed platforms such as Databricks, Spark provides complete flexibility and control but requires more operational expertise.
Key Features
- Supports distributed processing across large datasets.
- Enables batch processing and stream processing workloads.
- Supports SQL, Python, Scala, Java, and R development.
- Integrates with data lakes, warehouses, and cloud environments.
- Supports machine learning through MLlib.
- Enables scalable analytics and transformation workloads.
- Reduces processing times through in-memory computation.
- Provides open-source flexibility.
Pricing
Open source. Infrastructure costs apply.
Best For
Engineering teams requiring maximum flexibility and scalability.
Why Choose This Tool
Apache Spark remains one of the most versatile and scalable data processing technologies available and continues to power many commercial platforms in the market.
G2 Rating: 4.5/5
Gartner Rating: 4.6/5
#3 Snowflake
Snowflake has evolved far beyond its origins as a cloud data warehouse and is now a major Data Processing Platform supporting analytics, engineering, AI, and operational workloads. Organizations increasingly use Snowflake to process large volumes of structured, semi-structured, and unstructured information without managing infrastructure directly.
One of Snowflake’s biggest advantages is its separation of storage and compute. Traditional processing platforms often require organizations to scale infrastructure for all workloads simultaneously. Snowflake allows teams to scale processing resources independently, improving performance while controlling costs.
Compared with Databricks, Snowflake places greater emphasis on simplicity, SQL accessibility, and managed operations. Compared with AWS Glue or Dataflow, it provides a more unified environment for analytics and processing workloads.
The platform has become particularly popular among organizations building modern cloud analytics environments that require scalable processing without extensive operational overhead.
Key Features
- Processes structured, semi-structured, and unstructured information within a unified platform.
- Separates storage and compute resources for independent scaling.
- Supports large-scale analytics and processing workloads.
- Provides workload isolation to prevent resource contention.
- Supports Snowpark for advanced engineering and application development.
- Integrates with modern cloud ecosystems and lakehouse architectures.
- Enables AI, machine learning, and advanced analytics initiatives.
- Reduces infrastructure management complexity.
Pricing
Consumption-based pricing.
Best For
Organizations seeking managed cloud-based processing and analytics.
Why Choose This Tool
Snowflake is ideal for teams that prioritize operational simplicity, scalability, and analytics performance while minimizing infrastructure management.
G2 Rating: 4.5/5
Gartner Rating: 4.7/5
#4 Google Cloud Dataflow
Google Cloud Dataflow is Google’s fully managed data processing service built on Apache Beam. The platform supports both batch and stream processing workloads while providing automatic scaling and infrastructure management.
Organizations frequently choose Dataflow because maintaining large-scale processing infrastructure can be operationally expensive. Dataflow removes much of this burden by automatically provisioning resources and optimizing execution based on workload requirements.
Compared with Apache Spark, Dataflow requires significantly less infrastructure management. Compared with AWS Glue, it often appeals to organizations heavily invested in Google’s analytics, machine learning, and AI ecosystem.
The platform is particularly attractive for organizations building real-time analytics applications, streaming pipelines, and cloud-native processing architectures.
Key Features
- Supports both batch processing and real-time stream processing workloads.
- Built on Apache Beam for portability across processing environments.
- Automatically scales resources based on workload requirements.
- Integrates with BigQuery, BigLake, Pub/Sub, and Google Cloud services.
- Supports event-driven and streaming architectures.
- Enables low-latency analytics and operational processing.
- Reduces infrastructure management overhead.
- Supports AI and machine learning workflows.
Pricing
Usage-based pricing.
Best For
Organizations building Google Cloud-based processing pipelines.
Why Choose This Tool
Dataflow is one of the strongest options for teams that need managed stream processing and deep integration with Google’s analytics ecosystem.
G2 Rating: 4.4/5
Gartner Rating: 4.5/5
#5 AWS Glue
AWS Glue is Amazon’s serverless data integration and processing platform that helps organizations prepare, transform, process, and move information across AWS environments. The service has become a common choice for cloud-native processing architectures because it eliminates the need to manage dedicated infrastructure.
Organizations choose AWS Glue because processing workloads often fluctuate significantly. Traditional architectures require teams to provision infrastructure for peak demand, while Glue automatically scales resources based on actual workload requirements.
Compared with Databricks, AWS Glue provides a more AWS-centric experience. Compared with Apache Spark, it significantly reduces operational complexity but offers less flexibility and control.
The platform is especially popular among organizations standardizing on AWS for analytics, lakehouse architectures, and cloud modernization initiatives.
Key Features
- Provides serverless batch processing and transformation capabilities.
- Supports integration with Amazon S3, Redshift, Athena, and AWS analytics services.
- Automatically scales resources based on workload demand.
- Supports ETL, ELT, and processing workloads.
- Includes AWS Glue Data Catalog for metadata management.
- Enables cloud-native analytics architectures.
- Reduces infrastructure management effort.
- Supports AI and machine learning data preparation workflows.
Pricing
Usage-based pricing.
Best For
Organizations operating AWS-centric processing environments.
Why Choose This Tool
AWS Glue is often the most practical choice for businesses already invested in AWS services and looking for serverless processing capabilities.
G2 Rating: 4.2/5
Gartner Rating: 4.4/5
Increase your product visibility by reaching software buyers researching the best tools. Every submission is reviewed by our editorial team.
Feature My Tool →#6 Microsoft Fabric
Microsoft Fabric is Microsoft’s unified analytics and processing platform built around OneLake. Unlike traditional processing tools that focus only on engineering workloads, Fabric combines processing, analytics, reporting, governance, and AI capabilities within a single environment.
Organizations increasingly adopt Fabric because modern data stacks often become fragmented. Teams may operate separate platforms for storage, transformation, reporting, governance, and analytics. Fabric attempts to reduce this complexity through an integrated architecture.
Compared with Snowflake and Databricks, Fabric places greater emphasis on integration across Microsoft’s broader ecosystem. Organizations already using Power BI, Azure, Microsoft Purview, and Microsoft 365 frequently find Fabric particularly attractive.
The platform is gaining traction among enterprises looking to simplify analytics and processing architectures while maintaining governance and AI readiness.
Key Features
- Uses OneLake as a unified data foundation for processing and analytics.
- Supports engineering, analytics, reporting, governance, and AI workloads.
- Integrates deeply with Power BI, Azure, and Microsoft services.
- Provides lakehouse and warehouse processing capabilities.
- Supports real-time analytics and operational reporting.
- Includes governance, lineage, and security functionality.
- Reduces complexity across modern analytics environments.
- Enables AI-powered insights and analytics initiatives.
Pricing
Subscription-based pricing through Fabric capacities.
Best For
Organizations heavily invested in Microsoft technologies.
Why Choose This Tool
Microsoft Fabric is ideal for enterprises seeking a unified processing, analytics, governance, and reporting platform within the Microsoft ecosystem.
G2 Rating: 4.4/5
Gartner Rating: 4.5/5
#7 Apache Flink
Apache Flink has become one of the leading technologies for real-time Data Processing and stream processing workloads. While many traditional platforms were originally designed for batch processing and later added streaming capabilities, Flink was built from the ground up to process continuous streams of information with extremely low latency.
Organizations increasingly adopt Flink because modern applications often require immediate responses to changing business events. Fraud detection systems, recommendation engines, IoT platforms, financial trading applications, cybersecurity monitoring systems, and operational dashboards frequently depend on real-time processing rather than scheduled batch jobs.
Compared with Apache Spark Streaming, Flink generally offers stronger event-time processing and lower-latency streaming capabilities. Compared with managed platforms such as Google Cloud Dataflow and Confluent, Flink provides greater flexibility but requires more operational expertise.
The technology is widely used by organizations building event-driven architectures, operational intelligence platforms, and large-scale streaming environments.
Key Features
- Provides true stream-first processing architecture.
- Supports low-latency event processing at scale.
- Handles complex event processing and event-time analytics.
- Supports batch and stream processing within a unified framework.
- Enables real-time operational analytics and monitoring.
- Integrates with Kafka, cloud platforms, databases, and data lakes.
- Supports machine learning and AI data pipelines.
- Provides open-source flexibility and scalability.
Pricing
Open source. Infrastructure costs apply.
Best For
Organizations building real-time processing and streaming architectures.
Why Choose This Tool
Apache Flink is one of the strongest choices when real-time processing speed and event-driven intelligence are more important than traditional batch analytics.
G2 Rating: 4.5/5
Gartner Rating: Not Available
#8 Confluent
Confluent approaches Data Processing from an event-streaming perspective. Built around Apache Kafka, the platform enables organizations to continuously process, distribute, and react to information as events occur across business systems.
Many organizations choose Confluent because traditional processing architectures often introduce delays between event creation and business action. Confluent helps eliminate these delays by creating a real-time information backbone that connects applications, databases, cloud services, analytics systems, and operational platforms.
Compared with Apache Flink, Confluent focuses more on event distribution and streaming infrastructure. Compared with Databricks and Snowflake, it serves a different role by enabling continuous information flow between systems rather than primarily supporting analytics workloads.
The platform is widely adopted by organizations building customer-facing applications, operational intelligence systems, and modern digital platforms.
Key Features
- Enables real-time event streaming and data processing.
- Built on Apache Kafka’s distributed architecture.
- Supports event-driven applications and microservices.
- Integrates databases, applications, cloud platforms, and analytics systems.
- Provides stream governance, monitoring, and observability capabilities.
- Supports operational intelligence and real-time analytics.
- Enables large-scale distributed processing architectures.
- Reduces latency across business systems.
Pricing
Subscription-based pricing. Free tier available.
Best For
Organizations building event-driven and streaming-first architectures.
Why Choose This Tool
Confluent is an excellent choice when organizations need continuous information movement and event processing rather than traditional batch-oriented workflows.
G2 Rating: 4.4/5
Gartner Rating: 4.6/5
#9 Talend Data Fabric
Talend Data Fabric combines data integration, processing, governance, quality, and management capabilities within a unified platform. Organizations frequently adopt Talend because processing workloads often need to be closely connected with data quality and governance initiatives.
Unlike tools focused exclusively on speed and scale, Talend emphasizes trust, governance, and reliability throughout the processing lifecycle. This makes it particularly attractive for organizations operating regulated environments where data quality and compliance are critical requirements.
Compared with Databricks, Talend focuses more heavily on integration and governance. Compared with Informatica, Talend often appeals to organizations seeking a more developer-friendly and open architecture approach.
The platform remains popular among enterprises managing complex data ecosystems and compliance requirements.
Key Features
- Supports data processing, integration, governance, and quality initiatives.
- Provides low-code and developer-friendly workflow capabilities.
- Includes data quality validation and monitoring functionality.
- Supports cloud, hybrid, and multi-cloud architectures.
- Enables metadata management and governance workflows.
- Integrates with databases, applications, APIs, and cloud platforms.
- Supports analytics and reporting initiatives.
- Helps improve trust in processed information.
Pricing
Custom enterprise pricing.
Best For
Organizations combining processing, governance, and data quality initiatives.
Why Choose This Tool
Talend is a strong option when data processing must be tightly aligned with governance, quality, and compliance requirements.
G2 Rating: 4.3/5
Gartner Rating: 4.4/5
#10 Informatica Cloud Data Integration
Informatica Cloud Data Integration is one of the most established enterprise Data Processing and integration platforms in the market. The platform helps organizations process, transform, synchronize, and govern information across complex enterprise environments.
Many organizations choose Informatica because large-scale processing initiatives often span multiple departments, technologies, cloud platforms, databases, warehouses, and operational systems. Informatica provides a mature ecosystem capable of supporting these requirements.
Compared with Talend, Informatica generally offers broader enterprise adoption and ecosystem maturity. Compared with cloud-native platforms such as Hevo and AWS Glue, it focuses more heavily on enterprise governance, metadata, and large-scale operational requirements.
The platform remains a leading choice among large enterprises pursuing modernization, governance, and cloud transformation initiatives.
Key Features
- Supports large-scale cloud and hybrid processing workloads.
- Provides enterprise-grade integration and transformation capabilities.
- Enables governance, metadata management, and lineage tracking.
- Supports complex multi-cloud and hybrid architectures.
- Integrates applications, databases, warehouses, and cloud platforms.
- Includes automation and operational monitoring capabilities.
- Supports analytics, reporting, and modernization initiatives.
- Helps organizations manage enterprise-scale processing environments.
Pricing
Custom enterprise pricing.
Best For
Large enterprises managing complex processing and integration ecosystems.
Why Choose This Tool
Informatica remains one of the strongest choices for organizations seeking mature enterprise processing capabilities combined with governance and large-scale operational support.
G2 Rating: 4.3/5
Gartner Rating: 4.5/5
#11 StreamSets
StreamSets is a DataOps-focused platform designed to help organizations continuously process, monitor, and manage information across modern data architectures. Unlike traditional processing tools that focus primarily on moving data from one location to another, StreamSets emphasizes operational resilience and adaptability.
Organizations frequently adopt StreamSets because modern processing environments are constantly changing. APIs evolve, schemas change, cloud services update, and business requirements shift. These changes can break pipelines and create operational issues. StreamSets addresses this challenge through continuous observability, automated adaptation, and DataOps-oriented management.
Compared with Informatica and Talend, StreamSets places greater emphasis on operational agility and pipeline resilience. Compared with Databricks and Spark, it focuses more on pipeline management than large-scale compute processing.
The platform is particularly attractive to organizations operating complex cloud and hybrid environments where reliability and operational visibility are top priorities.
Key Features
- Supports continuous data processing across cloud and hybrid environments.
- Provides DataOps capabilities for monitoring and operational management.
- Detects schema changes and pipeline disruptions automatically.
- Enables resilient processing architectures with reduced downtime.
- Supports databases, applications, cloud platforms, and streaming environments.
- Improves visibility into pipeline performance and operational health.
- Reduces manual intervention associated with pipeline maintenance.
- Supports modernization and cloud transformation initiatives.
Pricing
Custom enterprise pricing.
Best For
Organizations implementing DataOps and large-scale pipeline operations.
Why Choose This Tool
Choose StreamSets when operational reliability and pipeline resilience are as important as processing performance itself.
G2 Rating: 4.4/5
Gartner Rating: 4.4/5
#12 Dataiku
Dataiku is a collaborative analytics, AI, and Data Processing Platform designed to help organizations prepare, process, analyze, and operationalize information at scale. The platform bridges the gap between technical teams and business users by providing a shared environment for analytics and AI initiatives.
Organizations increasingly choose Dataiku because processing information is no longer the final goal. Businesses ultimately want insights, predictive models, and AI-driven outcomes. Dataiku helps connect data preparation and processing activities directly to business intelligence, machine learning, and AI workflows.
Compared with Databricks, Dataiku focuses more heavily on collaboration and business adoption. Compared with traditional processing platforms such as Talend and Informatica, it provides stronger support for analytics and AI use cases.
The platform is especially popular among organizations pursuing enterprise AI and advanced analytics initiatives.
Key Features
- Supports data preparation, processing, analytics, and AI workflows.
- Enables collaboration between engineers, analysts, and business teams.
- Provides visual and code-based development environments.
- Supports machine learning and generative AI initiatives.
- Integrates with cloud platforms, warehouses, and data lakes.
- Includes governance and operationalization capabilities.
- Accelerates analytics and AI project delivery.
- Helps organizations move from processing to business outcomes.
Pricing
Custom enterprise pricing.
Best For
Organizations building analytics and AI-driven processing environments.
Why Choose This Tool
Dataiku is a strong choice when the goal is not just processing information but also operationalizing analytics and AI across the organization.
G2 Rating: 4.5/5
Gartner Rating: 4.6/5
#13 IBM StreamSets
IBM StreamSets combines StreamSets’ DataOps capabilities with IBM’s broader enterprise data management ecosystem. The platform helps organizations process, move, monitor, and govern information across complex hybrid and multi-cloud environments.
Organizations often choose IBM StreamSets because enterprise processing initiatives increasingly require governance, observability, compliance, and operational control in addition to scalability. The platform provides these capabilities while supporting modernization and cloud transformation programs.
Compared with standalone StreamSets deployments, IBM StreamSets offers tighter integration with IBM’s governance, analytics, and enterprise data management capabilities. Compared with Informatica and Talend, it places greater emphasis on DataOps and continuous operational visibility.
The platform is particularly relevant for large enterprises managing highly distributed data environments.
Key Features
- Supports large-scale data processing across hybrid and multi-cloud environments.
- Provides DataOps capabilities for monitoring and operational management.
- Enables continuous processing and pipeline observability.
- Supports governance and compliance initiatives.
- Integrates with IBM analytics and data management ecosystems.
- Detects operational issues before they impact downstream systems.
- Supports cloud modernization and migration initiatives.
- Improves reliability across enterprise processing environments.
Pricing
Custom enterprise pricing.
Best For
Large enterprises seeking DataOps-driven processing architectures.
Why Choose This Tool
IBM StreamSets is ideal for organizations that require enterprise governance, operational visibility, and processing reliability across complex environments.
G2 Rating: 4.4/5
Gartner Rating: 4.4/5
Which Data Processing Tool Should You Choose?
| Scenario | Recommended Tool |
|---|---|
| Best Overall | Databricks |
| Best Open Source Platform | Apache Spark |
| Best Managed Cloud Processing | Snowflake |
| Best Google Cloud Option | Google Cloud Dataflow |
| Best AWS Option | AWS Glue |
| Best Microsoft Option | Microsoft Fabric |
| Best Real-Time Processing | Apache Flink |
| Best Event Streaming Platform | Confluent |
| Best Governance-Focused Platform | Talend Data Fabric |
| Best Enterprise Integration Platform | Informatica Cloud Data Integration |
| Best DataOps Platform | StreamSets |
| Best AI & Analytics Platform | Dataiku |
| Best Enterprise DataOps Solution | IBM StreamSets |
Explore More Top Tools
Browse expertly curated software recommendations across hundreds of business categories.
Browse Top Tools →Conclusion
Data Processing Tools sit at the center of modern data architectures. Whether organizations are building analytics platforms, AI systems, operational applications, real-time dashboards, or machine learning pipelines, success ultimately depends on the ability to process information efficiently and reliably.
The market now spans several distinct categories. Databricks, Snowflake, Microsoft Fabric, and Dataiku provide broad platforms that combine processing with analytics and AI. Apache Spark and Apache Flink remain foundational open-source technologies powering many large-scale environments. AWS Glue and Google Cloud Dataflow offer managed cloud-native approaches, while Talend, Informatica, StreamSets, and IBM StreamSets address enterprise governance and operational requirements.
Organizations focused on batch analytics often gravitate toward Databricks, Spark, and Snowflake. Teams building real-time applications frequently evaluate Flink, Confluent, and Dataflow. Enterprises prioritizing governance and operational control commonly shortlist Informatica, Talend, and IBM StreamSets.
The best Data Processing Software depends on your processing requirements, cloud strategy, governance needs, AI initiatives, and long-term data architecture goals.
FAQs
1. What are Data Processing Tools?
Data Processing Tools help organizations collect, transform, validate, enrich, analyze, and distribute information across business systems. They support analytics, reporting, AI, machine learning, and operational applications.
2. What is data processing?
Data processing is the process of converting raw information into usable formats that support business decision-making, analytics, automation, and operational workflows.
3. What are the best Data Processing Tools?
Databricks, Apache Spark, Snowflake, Google Cloud Dataflow, AWS Glue, Microsoft Fabric, Apache Flink, and Confluent are among the leading platforms available today.
4. What is the difference between batch processing and stream processing?
Batch processing handles information in scheduled groups, while stream processing continuously processes information as events occur in real time.
5. Which Data Processing Tool is best for AI?
Databricks and Dataiku are among the strongest choices for organizations building AI, machine learning, and advanced analytics initiatives.
6. Which platform is best for real-time processing?
Apache Flink, Confluent, and Google Cloud Dataflow are widely recognized for real-time processing and streaming workloads.
7. Are there open-source Data Processing Tools?
Yes. Apache Spark and Apache Flink are two of the most widely adopted open-source Data Processing Technologies available today.
8. Which platform is best for AWS environments?
AWS Glue is often the preferred option for organizations operating primarily within AWS ecosystems.
9. How do Data Processing Platforms support analytics?
They transform, enrich, validate, and prepare information so that analytics platforms, dashboards, reports, and AI systems can generate accurate insights.
10. How do I choose the right Data Processing Tool?
Evaluate scalability, batch and streaming support, cloud compatibility, governance capabilities, AI readiness, operational complexity, and pricing before selecting a platform.